Mudanças entre as edições de "PJe 2.1"
(→Uma nova proposta arquitetural) |
(→A interação entre os serviços) |
||
| Linha 17: | Linha 17: | ||
=== A interação entre os serviços === | === A interação entre os serviços === | ||
| − | + | Cada contexto negocial terá portanto seu micro serviço, mas como estes serviços se comunicaram entre si? Muitas vezes o serviço de sessão de julgamento produzirá uma informação dizendo que o processo foi julgado, e neste momento o serviço de processo judicial deverá lançar uma movimentação. | |
| − | + | ||
| − | + | Este tipo de interação irá funcionar como uma coreografia, onde cada serviço sabe exatamente o que fazer conforme as informações surgem em seu ecossistema. As informações serão passadas aos serviços através de um serviço de filas de mensagens, sempre que um processo for julgado o sistema de sessão irá enviar ao serviço de fila uma mensagem com informações referentes aquele julgamento. Neste momento um serviço será responsável por consumir a fila e redirecionar as mensagens a outros serviços através de uma estratégia baseada no conceito de webhooks. Um ou vários serviços estarão inscritos para receberem as mensagens para um dado evento, o serviço de webhooks será responsável por inscrever os serviços e direcionar as mensagens. Quando o serviço de processo receber a mensagem via webhook ele deverá saber que é necessário lançar uma movimentação no processo, após isso ele também deverá notificar ao serviço de mensagem que uma nova movimentação foi lançada, de modo que os serviços que se interessam por movimentações ajam como devem agir. | |
| − | + | ||
| − | + | É importante que todo esse ecossistema funcione como uma nuvem de serviços, de modo que seja possível que o tribunal crie, por exemplo duas instâncias do serviço de consulta processual, ou até mais caso a demanda deste serviço cresça. Para isso é necessário um mecanismo de descoberta de serviços. Cada vez que iniciamos um serviço ele deve se registrar como um serviço ativo, esperando requisições de clientes. Este tipo de mecanismo funciona como um DNS e permite distribuir as requisições de maneira mais racional utilizando, por exemplo, um algoritmo round robin. | |
| + | |||
=== Um cliente para o PJe === | === Um cliente para o PJe === | ||
 Todos esse serviços precisam ser disponibilizados para o usuário, e para isso não usaremos mais o AngularJS, e sim o Angular que está em sua versão 4. A decisão de partir para a nova versão do Angular se motiva pelas grandes melhorias implementadas na versão, pela flexibilidade do TypeScript, pela rápida adoção da comunidade e pela baixa quantidade de código legado em angularJS no PJe 2. |  Todos esse serviços precisam ser disponibilizados para o usuário, e para isso não usaremos mais o AngularJS, e sim o Angular que está em sua versão 4. A decisão de partir para a nova versão do Angular se motiva pelas grandes melhorias implementadas na versão, pela flexibilidade do TypeScript, pela rápida adoção da comunidade e pela baixa quantidade de código legado em angularJS no PJe 2. | ||
Edição das 15h11min de 14 de setembro de 2017
Conteúdo |
Arquitetura PJe 2.1
Motivação
A necessidade de modularização do PJe em serviços menores e autônomos é um dos principais motivadores da arquitetura PJe 2.0. Nesse sentido, uma primeira versão arquitetural, desenvolvida pelo CNJ em conjunto com servidores de diversos Tribunais de Justiça, iniciou a separação das camadas de visão e controle do chamado backend da aplicação. Entretanto, ainda que tais iniciativas tenham mostrado ganho na escalabilidade do sistema, ainda eram insuficientes para atender, na íntegra, a expectativa da nova arquitetura. A modularização buscada até então ainda não servia de baseline para escalar o processo de “desidratação” do PJe 1.x e, em contrapartida, a “hidratação” do PJe 2.0. Com o passar do tempo, percebeu-se alguns problemas na concepção das fachadas REST como, duplicidade de codificação nas classes controladoras Java e as controllers da camada de visão (desenvolvida com o framework AngularJS); acoplamento entre a camada de visão e a fachada REST; e a dificuldade em se delimitar o escopo dos módulos negociais, tornando difícil a identificação de onde cada funcionalidade migrada do PJe 1 se encaixaria no PJe 2.
Tecnologias elencadas para o desenvolvimento da nova versão ainda não permitiam uma escalabilidade horizontal, de modo que o PJe 2 corria o risco de continuar sendo um monolito, ainda que mais bem estruturado e atualizado tecnologicamente, em comparação com a versão anterior. Outra característica da primeira implementação do PJe 2 que necessitou de melhorias foi o mecanismo de comunicação entre o PJe 1 e o PJe 2, onde havia um excesso de lookups entre os serviços para resolver questões de autenticação e autorização. Por último, as tecnologias utilizadas até então, obrigavam que o deploy do PJe 2 fosse disponibilizado no mesmo servidor de aplicação do PJe 1.
Uma nova proposta arquitetural
Tendo em vista as dificuldades tecnológicas para se atingir os objetivos arquiteturais da versão 2.0, a equipe do CNJ começou iniciou um fórum interno sobre os avanços necessários e as dificuldades que o PJe 2 nos trazia numa perspectiva de futuro. Apesar dos problemas citados, a nova arquitetura nos trouxe boas perspectivas a respeito da abordagem ao problema. Algo notório é que, sim, é possível migrar aos poucos os recursos do PJe 1 para uma nova arquitetura mais enxuta e com novas tecnologias. É indiscutível que o PJe precisa se renovar para abarcar o volume de processos e usuários que o sistema se propõe a atender, assim como não se discute que as tecnologias utilizada na versão 1 não serão mais adequadas à demanda que o sistema recebe diariamente.
A arquitetura modular monolítica, desenvolvida inicialmente, resolvia alguns problemas, mas ainda era permissiva com erros do passado. Os módulos não tinham escopos negociais bem definidos, o que permitiria que desenvolvedores acabassem por fugir ao escopo sempre que se vissem em alguma dificuldade para resolução de um problema. Esse tipo de abordagem ao código é o fator causador de diversos problemas enfrentados no PJe 1, as classes não possuem escopos bem definidos e portanto não é difícil notar, por exemplo, métodos de escopo do processo que fazem alterações a outras entidades do sistema, que nada têm a ver com aquele contexto negocial.
Todo esse panorama nos direcionou a estratégia de desenvolvimento de um sistema baseado em micro serviços. Uma abordagem ainda modular, mas não monolítica. A ideia é que cada escopo negocial bem definido seja envolto em um micro serviço. Por exemplo, poderíamos extrair toda a lógica negocial de audiências do PJe 1 e criar um serviço totalmente separado, com projeto autônomo, deploy e banco de dados próprios. Do ponto de vista do PJe 1, ele se tornaria um sistema cliente desse serviço nos momentos em que precisasse realizar atividades, como marcação e consulta de audiências, por exemplo.
Este tipo de abordagem permite que a implementação esteja focada no contexto negocial, facilitando o trabalho das equipes de negócio, desenvolvimento e testes. Outro benefício está na racionalização dos recursos tecnológicos, permitido ao tribunal que reserve para o serviço somente a quantidade adequada de recursos computacionais para que o serviço se comporte de maneira saudável.
O PJe passa, portanto a se comportar como um sistema mais moderno, dono de uma API composta por sua nuvem de serviços. Serviços estes que poderão ser disponibilizados, inclusive, para o público externo que necessite consumir informações por meio de suas aplicações proprietárias.
A interação entre os serviços
Cada contexto negocial terá portanto seu micro serviço, mas como estes serviços se comunicaram entre si? Muitas vezes o serviço de sessão de julgamento produzirá uma informação dizendo que o processo foi julgado, e neste momento o serviço de processo judicial deverá lançar uma movimentação.
Este tipo de interação irá funcionar como uma coreografia, onde cada serviço sabe exatamente o que fazer conforme as informações surgem em seu ecossistema. As informações serão passadas aos serviços através de um serviço de filas de mensagens, sempre que um processo for julgado o sistema de sessão irá enviar ao serviço de fila uma mensagem com informações referentes aquele julgamento. Neste momento um serviço será responsável por consumir a fila e redirecionar as mensagens a outros serviços através de uma estratégia baseada no conceito de webhooks. Um ou vários serviços estarão inscritos para receberem as mensagens para um dado evento, o serviço de webhooks será responsável por inscrever os serviços e direcionar as mensagens. Quando o serviço de processo receber a mensagem via webhook ele deverá saber que é necessário lançar uma movimentação no processo, após isso ele também deverá notificar ao serviço de mensagem que uma nova movimentação foi lançada, de modo que os serviços que se interessam por movimentações ajam como devem agir.
É importante que todo esse ecossistema funcione como uma nuvem de serviços, de modo que seja possível que o tribunal crie, por exemplo duas instâncias do serviço de consulta processual, ou até mais caso a demanda deste serviço cresça. Para isso é necessário um mecanismo de descoberta de serviços. Cada vez que iniciamos um serviço ele deve se registrar como um serviço ativo, esperando requisições de clientes. Este tipo de mecanismo funciona como um DNS e permite distribuir as requisições de maneira mais racional utilizando, por exemplo, um algoritmo round robin.
Um cliente para o PJe
Todos esse serviços precisam ser disponibilizados para o usuário, e para isso não usaremos mais o AngularJS, e sim o Angular que está em sua versão 4. A decisão de partir para a nova versão do Angular se motiva pelas grandes melhorias implementadas na versão, pela flexibilidade do TypeScript, pela rápida adoção da comunidade e pela baixa quantidade de código legado em angularJS no PJe 2.
O novo cliente angular estará totalmente separado e desacoplado dos serviços. Ele deverá se comportar como um cliente externo qualquer do sistema, utilizando-se da API de serviços do PJe.
Enquanto convive com o PJe 1, o nosso cliente Angular irá residir em um singelo iframe e talvez necessite se comunicar com a tela do PJe 1, como estarão em domínios separados a interação será efetivada através de mensagens entre janelas.
A nova versão do angular é baseada em componentes, o que nos permitirá criar um arcabouço de componentes que visem facilitar a implementação padronizada das telas do PJe, tendo como base a acessibilidade e experiência do usuário.
Como tudo se conecta
Descrevendo o diagrama acima temos o Angular 2+ como porta de entrada, cliente onde o usuário terá acesso aos vários serviços do PJe. O cliente angular irá acessar a API REST através de um serviço de borda, denominado “Gateway”. O Gateway nada mais é do que um serviço dentro da nossa nuvem de serviços, este conhece todos os outros e servirá de encaminhador das requisições do cliente.
Cada serviço, ao ser iniciado, se registra no “Discovery” informando que está disponível para aceitar as requisições. O Discovery também se encarrega de realizar load balancing entre os serviços registrados, desta maneira, se temos três instâncias de Processo, nosse serviço Discovery irá distribuir as requisições, de modo a não carregar uma mais que as outras.
O serviço OAuth2 se encarrega de controlar o acesso de usuários e serviços aos serviços da nuvem, sendo possível restringir o acesso a determinados serviços de acordo com as credenciais do usuário ou sistema.
Podemos perceber que cada micro serviço terá um contexto bem definido, inclusive sendo dono de seu próprio banco de dados, o qual poderá utilizar da tecnologia mais adequada para atender a proposta daquele serviço. Portanto não será mandatório que se use sempre um banco de dados relacional, por exemplo.
Os serviços irão ainda lançar seus logs para uma pilha ELK (Elastic, Logstash e Kibana). Os logs deverão observar não somente questões relacionadas a erros, mas também a sucesso das operações. Deste modo será possível avaliar a saúde dos serviços, se estão respondendo rápido, ou se estão muito lentos e com erros e precisam, portanto, de uma refatoração ou melhoria.
Como mencionado antes, os serviços funcionaram em modo de coreografia, onde cada serviço sabe bem o que fazer de acordo com o que acontece na nuvem. O RabbitMQ é um Message Broker que se responsabilizará por enfileirar as mensagens. Estas serão consumidas pelo serviço de webhooks que se encarregará de distribuir para os diversos serviços de nossa nuvem.
Sim, aquilo ali no topo é o PJe 1. Entenda o PJe 1 como um serviço também. Temos um serviço monolítico com muitas coisas que ainda não sabemos separar, portanto, inicialmente a versão legada servirá como um serviço sim, compondo a nova nuvem de serviços do PJe. A ideia é que a cada serviço “novo” criado o PJe legado se tornará um pouco menor. É importante dizer ainda, que o legado deverá se comportar como os outros serviços, escutando as filas do RabbitMQ, mandando mensagens para o RabbitMQ e autenticado através do serviço de autorização.
Estruturando um módulo/microserviço

Cada módulo, ou micro serviço, terá seu próprio domínio. Cada um deverá ser responsável por resolver um problema. A construção de módulo será iniciada pela equipe de negócio, que definirá um contexto bem definido para aquele pretenso serviço. Os requisitos negociais serão elicitados e a partir daí a equipe técnica começa a atuar.
A primeira tarefa da equipe técnica é definir a fachada REST, que irá prover as funcionalidades a serem acessadas pela camada de visão ou por outros módulos do PJe, ou ainda por outros sistemas externos.
Definidas as funcionalidades daquele novo serviço a equipe inicia a implementação do backend. Perceba que neste momento é possível que haja paralelismo entre a equipe que desenvolve o backend e a equipe que irá desenvolver o frontend. Inclusive é encorajador que se adote uma abordagem paralela. Equipes distintas trabalhando para frontend e backend evitarão acoplagem do serviço ao frontend, resultando em um serviço mais puros e enxutos que pode ser utilizado por outros sistemas, inclusive.
A dimensão de cada serviço pode ser variável. É importante que não sejam muito grandes nem muito pequenos. Um universo de muitos serviços pequenos pode tornar a coreografia dos serviços algo muito complexo de se manter, cada pequena alteração pode impactar em uma grande necessidade de reimplementação nos demais serviços. Os serviços também não devem ser grandes demais, um serviço muito grande representa algo que está tratando muitos problemas e acaba por se tornar um novo monolito.
O tamanho de um serviço é ideal quando, caso queiramos implementar todo o serviço, o tempo de codificação não passe de duas semanas. Certamente isso não é uma regra, mas uma notação a ser levada em consideração ao implementar novos serviços.
Cada micro serviço terá arquitetura simples, de modo a atender o seu contexto negocial. Dada a complexidade majorada de um determinada serviço, este pode ter um leve alteração arquitetural para atender a seu contexto. A abordagem de micro serviços permite um ambiente totalmente agnóstico de ponta a ponta, entretanto ter cada pedaço com uma tecnologia diferente torna a manutenção do sistema muito dependente de pessoas ou equipes específicas.
Tecnologias utilizadas
Projetos Envolvidos
- pje
- Projeto do PJe 1.X desenvolvido em Jboss Seam 2.2.2
- Contém a maior parte das regras de negócio implementadas
- Repositório: http://git.cnj.jus.br/pje/pje
- pje2-web
- Projeto do cliente Angular 4+ e do API Gateway da nuvem de serviços do PJe 2.1
- Repositório: http://git.cnj.jus.br/pje2/pje2-clientes/pje2-web
- pje2-discovery-service
- Serviço de descoberta utilizando o Netflix Eureka
- Responsável por registrar os serviços da nuvem do PJe 2.1
- Repositório: http://git.cnj.jus.br/pje2/pje2-infraestrutura/pje2-discovery-service
- pje2-webhooks-service
- Serviço responsável por receber e remeter eventos na forma de webhooks
- Repositório: http://git.cnj.jus.br/pje2/pje2-infraestrutura/pje2-webhooks-service
- pje2-elasticsearch-log
- Serviço responsável pela coleta e armazenamento de logs de auditoria do PJe
- Repositório: http://git.cnj.jus.br/pje2/pje2-infraestrutura/pje2-elasticsearch-log
Integração pje-legacy e a arquitetura 2.1
Registrando o PJe no Eureka
Para que fosse possível a integração do pje-legacy (PJe 1.x) com a nuvem de serviços proposta pela arquitetura 2.1, foi necessária a utilização de dependências do Netflix Eureka.
<dependency> <groupId>com.netflix.eureka</groupId> <artifactId>eureka-client</artifactId> <version>1.7.0</version> <scope>compile</scope> </dependency> <dependency> <groupId>com.netflix.eureka</groupId> <artifactId>eureka-core</artifactId> <version>1.7.0</version> <scope>compile</scope> </dependency>
Para a configuração do ambiente pje-legacy há ainda o arquivo eureka-client.properties, este é responsável por definir as configurações necessárias para o devido registro no pje2-discovery-service. No startup da aplicação o componente PjeEurekaRegister.java é inicializado e efetua o procedimento de registro da aplicação no Eureka. O arquivo eureka-client.properties define, entre outras informações, o endereço do Eureka, para que o PJe saiba onde se registrar. Como padrão, o PJe, está configurado para não se registrar em nenhum serviço de descoberta, para alterar este comportamento basta alterar a configuração pje2.cloud.registrar no arquivo integracao.properties.
Arquivos relevantes
- integracao.properties
- Define configurações de integração com a nuvem e com o cliente pje2-web
- eureka-client.properties
- Define as configurações a serem estabelecidas entre o pje-legacy e o pje2-discovery-service
- PjeEurekaRegister.java
- Responsável pela inicialização do processo de registro do pje-legacy no Eureka (pje2-discovery-service)
Embarcando o cliente Angular no PJe
Cofigurando o cliente Angular
Montando ambiente PJe 2.1
Ferramentas
- Eclipse Java EE (Versão mais atual) + JbossTools (Somente JbossAS)
- Eclipse STS (Spring Tool Suite)
- Visual Studio Code ou semelhante (Opcional)
- Java JDK 8 ou OpenJDK 8
- Git
- Wildfly (9 ou 10) ou JbossEAP7 (Ambos com o Mojarra 1.2)
Projetos necessários
- pje (http://git.cnj.jus.br/pje/pje)
- pje2-discovery-service (http://git.cnj.jus.br/pje2/pje2-infraestrutura/pje2-discovery-service)
- pje2-web (http://git.cnj.jus.br/pje2/pje2-clientes/pje2-web)
Clonando os repositórios
- Clonando o repositório pje (utilizar o branch PJE2-NG como base)
$ git clone git@git.cnj.jus.br:pje/pje.git $ ls pje pje-comum pje-web pom.xml $ git checkout PJE2-NG
- Clonando o repositório pje2-discovery-service (utilizar o branch master como base)
$ git clone git@git.cnj.jus.br:pje2/pje2-infraestrutura/pje2-discovery-service.git $ ls pje2-discovery-service pom.xml src
- Clonando o repositório pje2-web (utilizar o branch master como base)
$ git clone git@git.cnj.jus.br:pje2/pje2-clientes/pje2-web.git $ ls pje2-web frontend gateway pom.xml README.md src
Importando os projetos
Importando o projeto pje no eclipse
- No menu Arquivo selecione a opção Importar
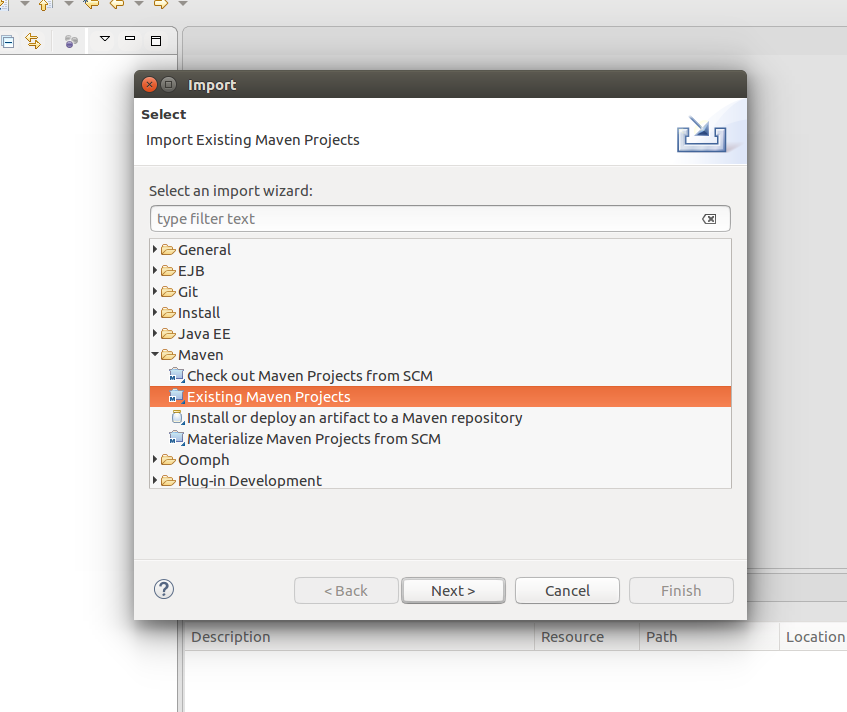
- Selecionar a opção Existing Maven Project

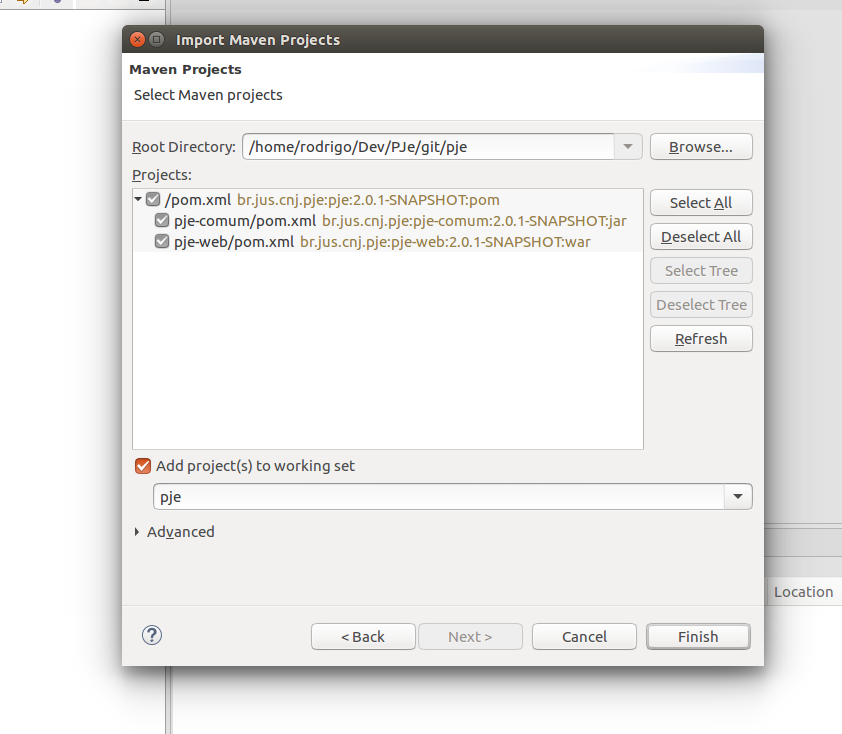
- Selecionar a pasta do projeto clonado

- Selecionar Finish
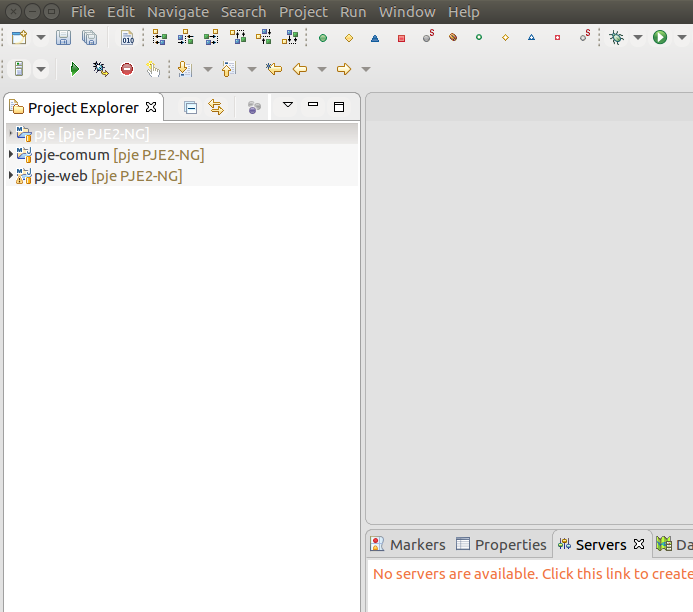

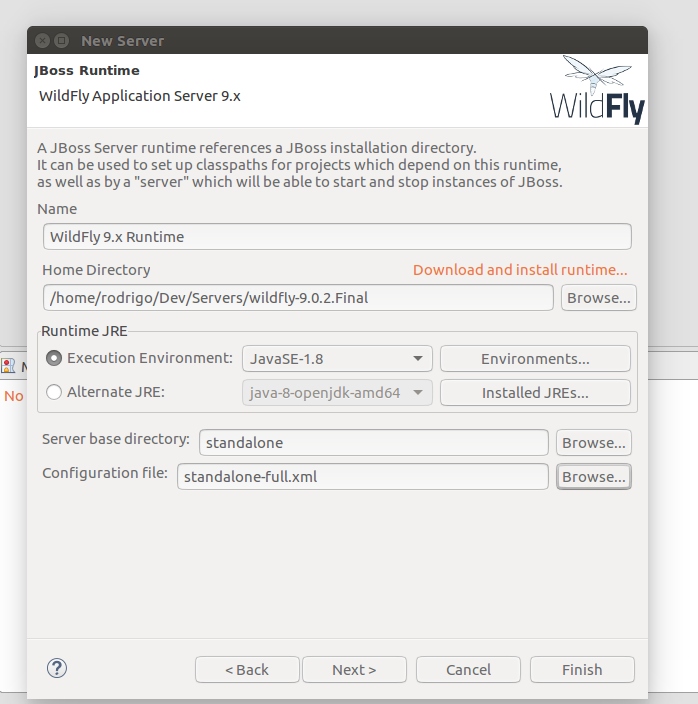
- Adicionar um novo servidor de aplicação
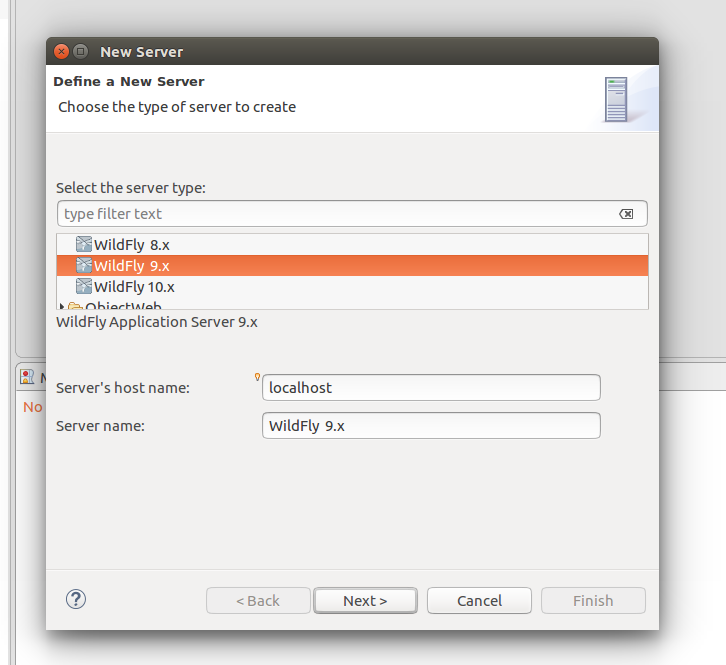

- Selecionar o diretório raiz do wildfly/jboss e utilizar o standalone-full.xml

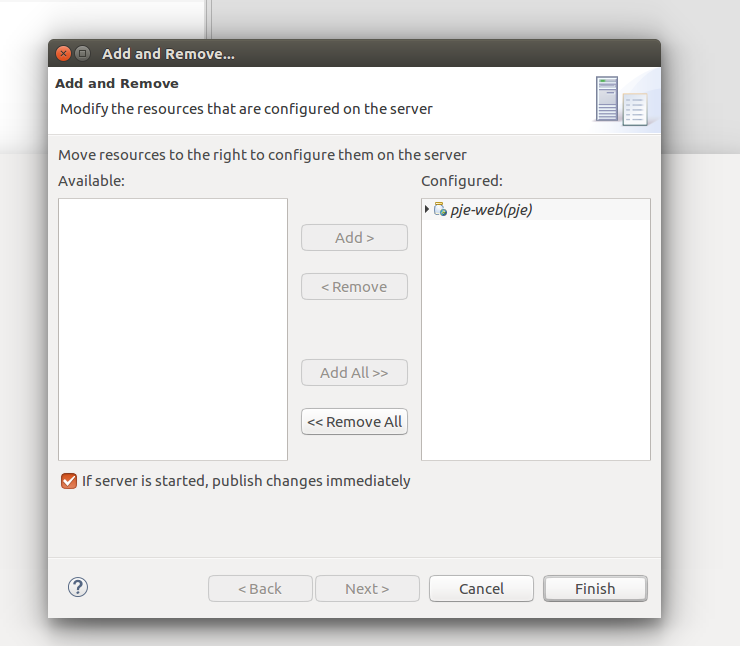
- Adicionar o projeto pje-web ao servidor de aplicação

Importando projetos pje2-web e pje2-discovery-service no STS
- Abrir o Eclipse STS
- No menu Arquivo selecione a opção Importar
- Selecionar a opção Existing Maven Project
- Selecionar a pasta do projeto pje2-web clonado

- Selecionar finish

- No menu Arquivo selecione a opção Importar
- Selecionar a opção Existing Maven Project
- Selecionar a pasta do projeto pje2-discovery-service clonado

- Selecionar finish

Iniciando os serviços
Inicializando os serviços SpringBoot no Eclipse STS
- Na ferramenta Eclipse STS selecione os projetos e efetue um Project>Clean...
- No Boot Dashboard execute o start ou debug dos dois serviços disponíveis

Inicializando o pje no Eclipse
- Na ferramenta Eclipse abrir o arquivo integracao.properties

- Alterar a propriedade pje2.cloud.registrar para o valor true, isso fará com que o pje se registro no pje2-discovery-service

- Iniciar o servidor de aplicação após efetuar o build do projeto
- Após o startup da aplicação acessar a página http://localhost:8761/ para verificar se o pje-legacy foi registrado no eureka

- Acesse o pje através de http://localhost:8080/pje-web
- Acesse o painel do usuário interno com papel de diretor de secretaria http://localhost:8080/pje-web/ng2/dev.seam#/painel-usuario-interno
